Title
無論用戶體驗或搜尋引擎如何,網頁的title標籤都必須盡可能簡單明瞭地描述整個網頁的內容。基於此因素,這也是網站管理員在設計網頁時操作SEO的最重要部分。只要注意以下幾點,就可以獲得良好的收益。
注意title標籤長度
設置網頁標題時,網頁設計師必須注意,關鍵字搜索結果頁上僅顯示前65-75個位元組,中文大約30到35個字,其後的文本將使用省略號。 “ ..”。因此,網站設計師在編寫內容時應注意文本的長度。這些字數限制也是大多數社交媒體網站的字數限制。但是,如果您有多組搜索關鍵字(或關鍵字特別長),則必須將不可避免的字元放置在標籤中,然後搜尋引擎可能會允許例外項超出字數。
重要的關鍵字放越前面越好
您擺在面前的關鍵字越多,您的網站排名就越有幫助,並且會吸引更多用戶點擊您的網站。這對於網頁設計期間的SEO優化排名至關重要。
包含品牌名稱
在Moz,我們希望將品牌名稱放在末尾,這將增加品牌知名度並提高點擊率。如果它是知名品牌的主頁,有時您還會看到品牌名稱放在前面。但是,當然,放在前面的次數越多,權重就越高,因此無論是品牌名稱還是關鍵字,都必須引起重視並考慮重點。
留意文句流暢具吸引力
Title標籤必須光滑且具有吸引力,這是您的品牌傳達給觀眾的第一印象。建立引人注目的標題可以説明您在搜索結果頁面上比其他網站印象深刻,並進一步吸引更多的訪客閱讀您的網站。這不僅是關鍵字優化,而且是用戶體驗優化。
Title內容顯示在Web流覽器的頂部,通常是社交媒體轉發和共用的主題。如果標題標籤中設置的關鍵字與用戶的搜索詞匹配,則它們將在搜尋引擎結果頁面上清晰地標記(粗體或紅色),以吸引用戶的注意力和點擊率。
最後,具有關鍵字和魅力的標題的最重要因素是搜尋引擎的排名。根據Moz一年兩次的SEO行業領導者調查,有94%的人認為在標題標籤中包含關鍵字對於提高排名至關重要。
Title的相關文章
http://moz.com/learn/seo/title-tag
Meta
Meta標籤的主要功能是向搜尋引擎提供網站的其他相關資訊。以下是幾個基本的meta標記及其用法。放置此標籤時,最好與瞭解網頁設計的人員進行討論。
Meta Robots
Meta Robots标记用于控制网页中主要搜索引擎蜘蛛的活动。以下是几种Meta Robots的用途:
index或noindex用來告訴搜尋引擎是否要對該頁面進行爬網和建立索引。如果您不願意,可以使用「 noindex」,否則預設情況下將對索引進行爬網,因此無需編寫「 index」。
Follow或nofollow告訴搜尋引擎是否應跟蹤此頁面上的連結。如果使用「 nofollow」,搜尋引擎將忽略頁面上的任何連結,並且不會用作計算排名的參考。通常,預設情況下使用「跟隨」。
例子:
<meta content=”NOINDEX, NOFOLLOW” name=”ROBOTS” />
- noarchive是禁止搜尋引擎保存網頁快取連結。默認狀態下,搜尋引擎會保存曾經抓取索引過的網頁內容,並可經由搜尋結果頁面的快取連結展現。
- noodp或noydir是特殊的標籤,告訴搜尋引擎不要抓取從開放式目錄(DMOZ)或Yahoo!目錄的描述。
- X-Robots-Tag HTTP標頭也有相同的功用。這種技術尤其適用在非HTML的內容,例如圖片。
- 以上Meta標籤必須警慎處理,以免造成網站收錄不全情況發生,如果不了瞭解影響範圍,可以請配合網頁設計人員代為處理
Meta Description

Meta description標籤是頁面內容的簡短描述。儘管網站排名不受Meta description的影響,但它是使用者瞭解您網站內容的主要來源。
明確地說,meta description標籤是用於吸引用戶注意力的網站廣告文案,這是優化搜尋引擎行銷的重要組成部分。在搜索結果頁面上的許多網站中,使用關鍵字(請注意,Google會將與使用者搜索詞匹配的文字加粗)以編寫簡單且易於閱讀的說服力的網站說明,以提高網站的點擊率。
Meta description沒有長度限制,但是由於常規搜尋引擎會剪切超過160個字元的句子,因此最好將單詞數保持在160個字元(約80個漢字)以內。對於沒有元描述標籤的網站,搜尋引擎將改為獲取頁面上的文本內容。對於具有多個關鍵字和不同主題的網站,這通常是最合適的方法。
不再重要的meta標籤
Meta Keywords: meta keywords標籤曾經一度受到高度重視,但是對於優化當前SEO搜尋引擎而言,它不再那麼有價值。仍然有許多網頁設計師喜歡添加此標籤,但對於Google來說,它沒有SEO效果。如果您想瞭解為什麼放棄和忽略meta keywords,請參閱Search Engine Land的Meta Keywords Tag 101。。
Meta Refresh,之後的Meta Revisit,Meta Content-type等:儘管這些標籤仍在SEO搜尋引擎優化中使用,但它們已逐漸下降。有關更多詳細資訊,請參閱Google’s Webmaster Tools Help幫助
URL結構
URLs – 文件在網絡上的地址 – 會出現在幾個重要的位置,從搜尋的角度來說含有極大的價值。
URLs出現的地方:

如上圖,顯示在搜尋引擎結果頁面上的URLs文字結構若包含用戶的搜索詞,有很大機率提高網站點擊率與知名度。

URL也顯示在瀏覽器的地址欄。雖然對搜尋引擎的影響不大,但不符合邏輯的糟糕網址文字結構可能會導致負面的用戶體驗。上圖是簡單易懂的網址文字結構,用戶可很容易的了解這是蘋果公司在台灣的iPhose SE的產品頁面。
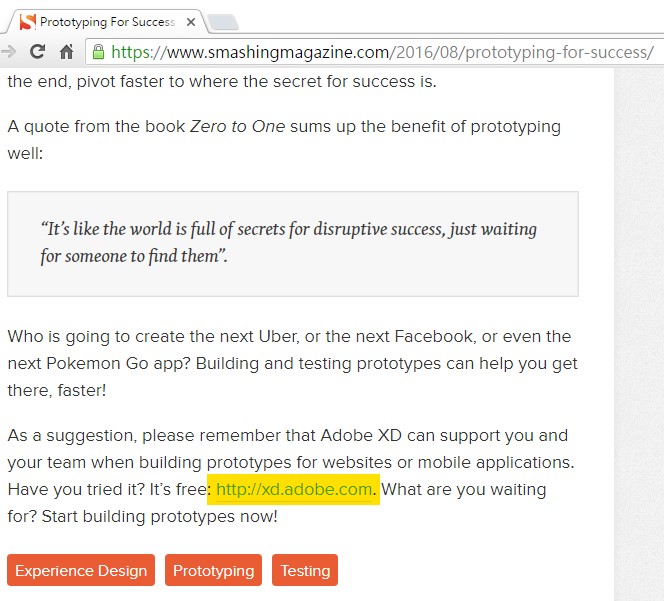
網址若被引用,有時也會以連結的方式出現在引用者的文章內,如上圖。
URL架構方針
同理心
請把自己當作URL的訪客。最好設計您的URL文本結構以呼應網頁文章的內容。但是,沒有必要將所有詳細資訊放在主題中,而是將其放在URL中。蘋果網站的上述文本結構可以用作示例。
越短越好
儘管具有可回顯文本的URL結構很重要,但減少長度和斜杠將使您更容易在email,博客,文本消息等中複製和共用URL,也將更易於完全出現在搜尋引擎結果頁面上。使用關鍵字非常重要(但是過度使用非常危險!)請記住在URL文本結構中包含關鍵字,但是請不要認為您投放的SEO越多越好,則可能會將其視為垃圾訊息!
使用靜態網址
良好的URL結構不應包含太多參數,數位和符號,並且易於使用者識別。在Apache中使用mod_rewrite或在Microsoft中使用ISAPI_rewrite可以輕鬆實現動態URL,並將它們轉換為易於閱讀的靜態URL。即使該URL僅包含一個動態參數,也可能導致較低的搜尋引擎排名和索引。
使用連字號分隔文字
並非所有Web應用程式都能準確區分底線(_),加號(+)和空格( ),因此可以使用連字號(-)代替文本之間的分隔。例如,上面的示例:google-fresh-factor。
內容的標準和重覆的內容
重複的內容是任何網站上最麻煩,最困難的問題之一。在過去的幾年中,搜尋引擎已開始嚴厲打擊並降低具有重複內容的網站的搜索排名。
標準化的原因是,兩個或多個重複版本的網頁出現在不同的URL上,並且最常出現在使用文章討論類型(CMS)的網站上。例如,除了普通的網路版本,相同內容的網路內容還提供印刷版本。有時同一篇文章會出現在不同的網站上。對於搜尋引擎而言,這是巨大的,他們不知道應該向使用者呈現哪些內容。在SEO搜尋引擎得到優化的世界中,這是重複的。


搜尋引擎討厭重複的內容。為了向用戶提供最佳的搜索體驗,他們很少將頁面的所有重複版本放在搜索結果頁面上,作為替代,他們將確定哪個頁面最有可能是原始頁面,並減少那些繁瑣的頁面。在搜尋引擎上重複的頁面。 (以上圖片為插圖)。
標準化是指定唯一內容網頁的方法,並且只能輸入一個URL。如果當時您的網頁設計有多個版本,您可能會開始考慮上述三個網站中的哪個是唯一的標準URL。

但是,如果網頁設計師使用301重定向這些頁面,則搜尋引擎將僅顯示其中一個頁面。
當潛在網頁合併為一個頁面時,它們不僅會停止相互競爭以進行排名,而且還會創建一個更強大,更相關的網頁。這對您的網頁在搜尋引擎排名中的提升有積極作用。 (上圖)
使用標準化標籤
規範URL標記是將重複內容聚合到單個URL中的另一種方法。此方法還可以跨網站,從一個域的URL到另一域的URL。在重複的內容上使用標準化標籤可以提高您要排名的頁面在搜尋引擎中的排名。
上面的命令告訴搜尋引擎,網站上任何重複的內容和索引排名都指向http://3dayseo.com。換句話說,只有http://3dayseo.com是統一標準的進入點。

從SEO角度來看,標準化標籤與301重定向非常相似。從本質上講,它是讓搜尋引擎知道所有重複的頁面都指向一個頁面(與301相同),但是標準化標籤不會跳轉到新的URL。
有關不同類型重複的更多資訊,可參考皮特博士的這篇文章。
複合式摘要

您是否在搜索結果頁面上看到過5星級評價?當搜尋引擎從「複合摘要」的網頁中抓取資訊並將其顯示在搜索結果中時,複合摘要是一種結構化資料,允許網站管理員將更豐富的內容資訊標記到搜尋引擎中。
儘管使用複合摘要和結構化資料並不是搜尋引擎友好性的必要元素,但是其日益普及的使用意味著使用它的Web設計人員在某些情況下具有優勢。
結構化資料意味著在您的內容中添加標籤,以便搜尋引擎可以輕鬆識別其內容類別型。 Schema.org提供了一些結構化標籤,包括商家,產品,評論,銷售,食譜和事件的示例。
通常,搜尋引擎包含在搜索結果頁面中的結構化資料包括使用者評論(星級)和作者個人資料(照片)。互聯網上有一些學習資源可供參考,包括:information at Schema.org 與 Google’s Rich Snippet Testing Tool。
複合式摘要的使用
假設您在博客上發佈了SEO研討會消息。在一般的HTML中,您的代碼可能如下所示:

現在,在獲得結構化資料之後,我們可以告訴搜尋引擎更多具體資訊,最終結果可能像這樣:

捍衛您的網站
文章被盜用如何竊取您的排名?
不幸的是,Internet上充斥著不道德的網站,其業務和流量模式取決於複製其他網站的內容(有時會修改結構)並在自己的網站上重複使用。這種檢索您的內容並將其重新發佈的做法稱為「scraping」,並且那些複製文章的網站在搜尋引擎中通常排名很高,並且通常高於原始網站。
當您發佈任何形式的資訊(例如RSS或XML)時,請確保通知主要博客平臺和跟蹤服務平臺(Google,Technorati,Yahoo!…等)。可以在各自的網站上找到跟蹤Google和Technorati使用情況的方法,也可以使用Pingomatic。如果使用定制的發佈平臺,則最好要求開發人員在發佈後包括自動檢測。
接下來,您可以使用盜賊的懶惰性質來與他們戰鬥。大多數竊賊在竊取文章後不會重新編輯該文章,而是直接發佈該文章。因此,只要被盜的文章包含「指向您網站的連結」,就可以確保搜尋引擎知道您是這些文章的原始作者。為此,最好使用絕對連結作為內部連結結構,而不是相對連結。當然,相比使用<a href=”../”Home</a>連結到您的網站,您應該使用<a href=”http://3dayseo.com/”>Home</a>來做替代。這樣,當小偷竊取您文章的內容時,該連結仍指向您的網站。
實際上,有很多方法可以防止物品被盜,但沒有辦法完全消除它。您應該意識到,網站的曝光率越高,文章被盜的可能性就越高。你們中的大多數人都可以忽略此問題,但是如果情況變得非常嚴重並影響流量和排名,則可能需要考慮使用合法管道。 Moz提供了一些被盜後處理您的文章的方法,請參考以下連結:Four Ways to Enforce Your Copyright: What to Do When Your Online Content is Being Stolen.
來源:MOZ
如果你還未閱讀其他章節,可使用以下傳送門:
- 第一章:搜尋引擎的運作方式
- 第二章:與搜尋引擎的互動
- 第三章:為何SEO搜尋引擎行銷是必要的?
- 第四章:SEO搜尋引擎最佳化的基礎開發與設計 (上)
- 第五章:SEO搜尋引擎最佳化的基礎開發與設計 (下)
評論(0)